Introduction To Celery
Celery is a distributed task queue, which means it spreads work across a bunch of threads and machines. If you go through the work of defining tasks, you have a scalable entity (the workers) that you can use as a knob to scale with volume. Since you’re putting heavy asynchronous work on a trivially easy-to-scale part of your system, it alleviates the burden elsewhere and makes your system more scalable.
I’ve spent the last couple months working with Celery at work, and I figured I’d relate the experience for anybody who’s in the same shoes I was in 3 months ago.
Each piece of Celery is simple to understand—the thing is there’s a lot of pieces.
What is a task?
The core unit of work in Celery is a task. Basically, a function that you need to run asynchronously or on a schedule. Everything in Celery is built around tasks - scheduling them, managing them, getting their results, scaling the workers to perform them more quickly.
Celery Architecture
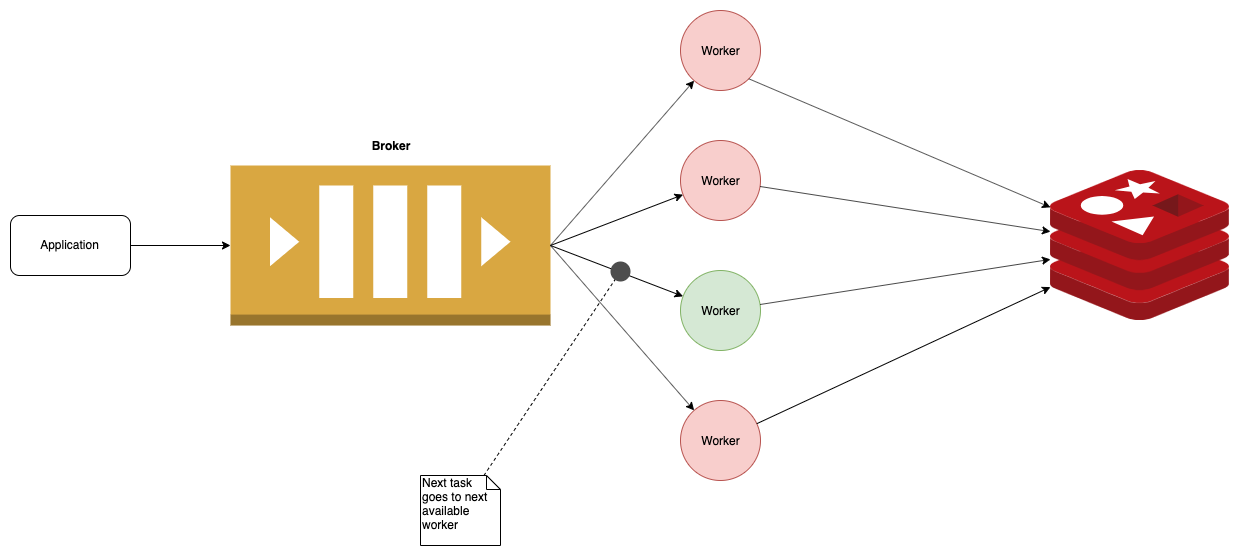
Here we have a basic Celery architecture. We have a broker, usually RabbitMQ (sometimes Redis). A task is published to the broker, from some application.
The task is then taken from the broker, and run on a Celery worker. Note that tasks are always kicked off via the broker, even if it’s subtask. A related minor caveat is that your arguments must always be JSON serializable.
Writing a Task
A task is simply a Python function, with the @task decorator. In case you’re unfamiliar with Python decorators, here’s a review.
Let’s define a simple task that adds 2 numbers.
1@task2def add(x, y):3 return x + yI assure you running it is much worse.
Running a Task
It’s important to remember that all tasks are invoked over the broker. What does that payload look like when we put a task on the broker? Let’s revisit our add task. (In this example, we’re using RabbitMQ).
The fairly cleaned version of the RabbitMQ message:
1properties.headers.task: tasks.add2payload: [[4,5],{},{"callbacks":null,"chain":null,"chord":null,"errbacks":null}]There’s a header with the task name. Then there’s a payload, of the following format:
1[args, kwargs, task_metadata]Our main interest is the args. Now, how do we put that on the queue?The most basic way is through the Celery shell. Run celery shell in you directory (assuming you have all your dependencies available, I do this via pipenv).
Then, call add.apply_async(args=[4, 5]). If you have a worker running in another shell (celery worker, to start one up), then it will invoke the tasks.
I understand this is not the most thorough guide to getting a Celery project started. The point is more to understand all the pieces than to be coding along.
Running a task in the wild
In an actual app, there are a few ways to actually run the task. If you’re using a Python framework, like Django, you can just straight up invoke the task using the tasks delay or apply_async functions, just like above. Here is a nice example of that. Note that even though you’re in Python calling a Python function, it is still serialized and invoked via the broker. Even subtasks of a task are serialized and invoked via the broker.
Calling Celery Tasks in Other Languages
Here are just a few Celery client libraries that allow you to invoke tasks from other languages, if you have a Spring or a Go microservice, for instance.
Scheduling Tasks
Scheduling tasks in Celery is damn easy. The entity that does the scheduling is called Beat. So, you just configure the Beat schedule, which is just a property on your app object—a Python dictionary.
1app.conf.beat_schedule = {2 'add-every-30-seconds': {3 'task': 'tasks.add',4 'schedule': 30.0,5 'args': (16, 16)6 },7}8app.conf.timezone = 'UTC'Note that you can use the Celery supported crontab() function in place of 30.0 to design more complicated schedules.
There’s not much more to scheduling tasks; the API for this is amazing. Note that it lives with your Celery app, so it is version controlled, unlike if you were just using lambdas through the AWS console (barring the use of some infrastructure as code like Terraform).
Managing Tasks
My absolute favorite part of using Celery is the task management dashboard called Flower.
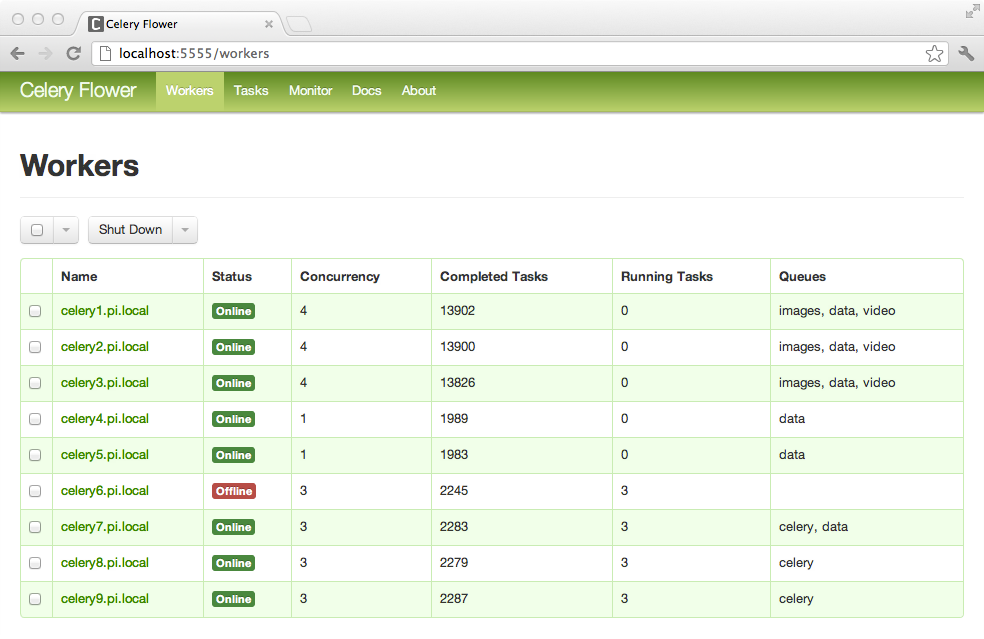
You can monitor your workers, see all the tasks that have been run (you can even see their arguments!). This made diagnosing failures pretty trivial and was a huge pro for Celery.
Cons of Celery
- The amount of devops work. You will need a worker, Flower, and Beat all running (that’s 3 separate processes). There’s a bit of a hurdle of initial configuration.
- It’s in Python. This could be a pro or a con depending on your team’s stack. Where I work it was a con, but I did thoroughly enjoy myself, so no complaints here.
I will say, if you’re using Django, Celery would be a no brainer.
Lightning Round ⚡
Now let’s just answer a bunch of quick questions about Celery, since we’ve covered the basics.
What’s a chord?
In Celery, you can put tasks in a group. Sometimes there’s a special task that you only want to execute after all tasks in a group have completed. That special task is a chord.
Can you do pub/sub with Celery?
This is something I’ve been thinking about a lot myself. Celery doesn’t support this out of the box. However, the most common results backend is Redis, and so I don’t think building support for it with Redis keyspace notifications would be too hard.
There does appear to be a library for it, but it’s in it’s early stages, so I wouldn’t use it in production quite yet.
Alternatively, there’s a lot of different options for the results backend (e.g. RabbitMQ, Cassandra, Elasticache, etc.). I think it would be best to use one of those, perhaps even a custom one, like Kafka (which Celery doesn’t support out of the box).
Let’s say I have a task that needs to make an HTTP request. Does Celery use blocking I/O?
By default, it does. But, you can enable highly scalable non-blocking I/O, through the Eventlet library. Similar to Node’s libuv, it uses asynchronous OS system calls to subscribe to I/O handles.
Wow! You read the whole thing. People who make it this far sometimes
want to receive emails when I post something new.
I also have an RSS feed.